
Stable Diffusionの既存モデルで画像生成していると現状で満足できなくなってきます。
そうです、自分好みの絵や写真を生成したい!と。
好きなキャラクター、有名人、芸能人を好きに生成させいろんなポーズをとらせたい。
画像生成の一番の目的はこれではないでしょうか。
この記事ではMacでのLoRAの作り方を紹介します。
有名人のコラ、アイコラ、ディープフェイクはネットに公開してはいけませんよ!
(2023/5/14 追記)
LoRAを発展させたファインチューニング手法LoConが登場しました。
LoConの作り方はこちらで紹介しています。

LoRAとは
Low Rank Adaptationの略で、Stable Diffusionのファインチューニング手法の一つです。
ファインチューニングとは、既存モデルに対して新たなデータで学習し直す手法のことです。
新たなデータに生成したいキャラの画像を用いることで、そのキャラを生成しやすくできるわけです。
Stable Diffusionのファインチューニング手法には大きく分けて4つあります。
LoRAはその中でも手軽、軽量で効果的です。
今後最も発展していくと思います。
LoRAについて理論を詳しく知りたい方はこちらをご覧ください。

LoRAの作り方
以下の人を対象に説明します。
私自身が以下に該当したため、同じ悩みの人の助けになればと思います。
- Mac(M1)マシンのローカルでLoRAを作りたい
- Stable Diffusion Web UIの機能でLoRAを作れない
- cloneofsimoでLoRAを作れない
- kohya_ssのGUIでLoRAを作れない
WindowsではなくMacだから、cudaではなくmpsだから、GPUメモリが足りないから
が動かない主な原因だと思います。
準備するもの、環境
- M1チップ搭載のMac(MPS)
- kohya_ss氏のGit
kohya_ss氏のGit
LoRAを作成するツールとしてkohya_ss氏のGitを使用します。
LoRAの他にDreamBoothやTextual Inversionも作成することができます。
以下でGitをクローンしてください。
git clone https://github.com/bmaltais/kohya_ss本来はGUIでファインチューニングできるのですが、ここではCUIで実行する方法を紹介します。
Windows以外の方、特にLinuxで学習させたい方はCUIだと都合が良いと思います。
ここではMac用の説明ですが、LinuxでもGPUがcudaに変わるだけで動くはずです。
インストールするpythonライブラリ
以下をpipやcondaでインストールしてください。
その他にも足りないものがあれば適宜インストールしてください。
- torch(バージョン2.0)
- torchvision(バージョン0.15)
- accelerate
- albumentations
- einops
- voluptuous
学習用画像の準備
画像は100枚程度で充分です。
正則化画像やキャプションは用いなくても学習できます。
画像はすべて同じサイズにしておきます。
私は512×512で準備することが多いです。
同じサイズの画像の作り方は以下をご覧ください。
画像は以下のようなフォルダ構成にして格納してください。
親フォルダ ━ 子フォルダ ┳ 画像1
┣ 画像2
┣ ・・・
┗ 画像n
親フォルダの名称は適当で問題ありませんが、子フォルダの名称は以下のルールに従ってください。
繰り返し回数_identifier class
- 繰り返し回数:学習の繰り返し回数(※後述するが、epoch数ではない)
- identifier:学習させたい物体の名称(意味のない3文字が望ましい)
- class:identifierが属する物体の名称
例えばペットの猫 トラキチのLoRAを作りたい場合、5_trk cat のようなフォルダ名にします。
accelerateの設定
Accelerateは、デバイスを自動で切り替えながらpytorchの処理をするpythonライブラリです。
AIモデルを学習、推論するときはGPUで動かすと思いますが、あらかじめaccelerateを設定しておくことでpythonコードに明示する必要がなくなります。
cudaとかmpsとかcpuとか書き換えなくて良いってことね
ただ、正しく設定しないと動かないため、以下をで設定してください。
accelerate config対話式で設定します。
意味がわからなければ私の設定を参考にしてみてください。
| 質問 | 回答 |
|---|---|
| In which compute environment are you running? | This machine |
| which type of machine are you using? | No distributed training |
| Do you want to run your training on CPU only? | NO |
| Do you wish to optimize your script with torch dynamo? | NO |
実行ファイルの作成
以下のようなシェルファイルを作成してください。
export PRE_MODEL_NAME="runwayml/stable-diffusion-v1-5"
# export MODEL_CONTINUE="trk-000002-state"
export DATA_DIR="./traindata"
export OUTPUT_DIR="./models/trk"
export MODEL_NAME="trk"
export PROMPT_FILE="./prompt.txt"
accelerate launch \
"train_network.py" \
--network_module=networks.lora \
--pretrained_model_name_or_path=$PRE_MODEL_NAME \
--train_data_dir=$DATA_DIR \
--output_dir=$OUTPUT_DIR \
--output_name=$MODEL_NAME \
--logging_dir="./log" \
--resolution=512,512 \
--max_train_epochs=10 \
--train_batch_size="1" \
--prior_loss_weight=1.0 \
--learning_rate="1e-4" \
--cache_latents \
--gradient_checkpointing \
--save_every_n_epochs=1 \
--save_state \
--sample_prompts=$PROMPT_FILE \
--sample_every_n_steps=140 \
--sample_sampler="k_euler_a" \
# --v2
# --resume $MODEL_CONTINUEシェルの意味はこちらです。
主に実行オプションの説明です。
| 行数 | 項目 | 意味 |
|---|---|---|
| 1 | PRE_MODEL_NAME | 学習元となるモデルファイル Hugging Faceにあるモデルの場合、上記のように指定するとネット経由で取ってきます。 ローカルにあるモデルファイル(ckpt、safetensorsなど)も指定可能。 |
| 2 | MODEL_CONTINUE | 継続学習する際のモデル save_stateオプションを指定して学習したモデルでないと継続学習できません。 |
| 3 | DATA_DIR | 学習データのある親フォルダ 子フォルダではない点に注意。 |
| 4 | OUTPUT_DIR | 学習したモデルを保存するフォルダ |
| 5 | MODEL_NAME | 学習したモデルの名前 |
| 6 | PROMPT_FILE | プロンプトが書かれたファイル 学習の途中経過を確認するために準備します。 |
| 9 | train_network.py | 実際にLoRA学習を実行するファイル DreamBoothの場合、train_db.py Textual Inversionの場合、train_textual_inversion.py |
| 10 | network_module | LoRA実行に必須のオプション |
| 16 | resolution | 学習画像のサイズ 幅, 高さの順で指定するが、1つだけ指定すると幅と高さが同一と見なされる。 |
| 17 | max_train_epochs | 学習エポック数 最終的なステップ数は、学習画像数×繰り返し回数×エポック数 となります。 |
| 18 | train_batch_size | 一度に並列処理する画像数 メモリに余裕がなければ1でよいです。 |
| 19 | prior_loss_weight | |
| 20 | learning_rate | 学習率 これは職人用です。1e-4〜1e-6にすることが多いです。 |
| 21 | cache_latent | |
| 22 | gradient_checkpointing | 重み計算を徐々に処理する これは使ってみてもあまり効果がわからないかも。 |
| 23 | save_every_n_epochs | モデルをNエポックごとに保存 |
| 24 | save_state | 継続学習用のファイルを保存 |
| 25 | sample_every_n_steps | サンプル画像をNステップごとに生成 |
| 26 | sample_sampler | サンプル画像を生成するときのサンプラー |
| 28 | v2 | Stable Diffusion のv2系を学習元モデルにする際のオプション |
| 29 | resume | 継続学習する際のオプション |
その他にもオプションはありますので、以下を参考にしてください。
中には指定するとMacでは動かないものもありますのでご注意を。
(オプションが悪いのではなく、自分の環境に合わないというわけです。)
https://github.com/bmaltais/kohya_ss/blob/master/train_README-ja.md
https://github.com/bmaltais/kohya_ss/blob/master/train_network_README-ja.md
それではいよいよ以下を実行し、LoRAの学習を開始しましょう!
./作成したシェル.shLoRAの使い方
LoRAの格納
LoRAは上記で設定したOUTPUT_DIRに格納されます。
拡張子は.safetensorsですので、そのファイルをStable Diffusion Web UIの以下のフォルダに格納します。
models/LoRA/Stable Diffusion Web UIで実行
Stable Diffusionを起動し、以下のようにLoRAを適用します。
Stable Diffusion Web UIについてはこちらをご覧ください。

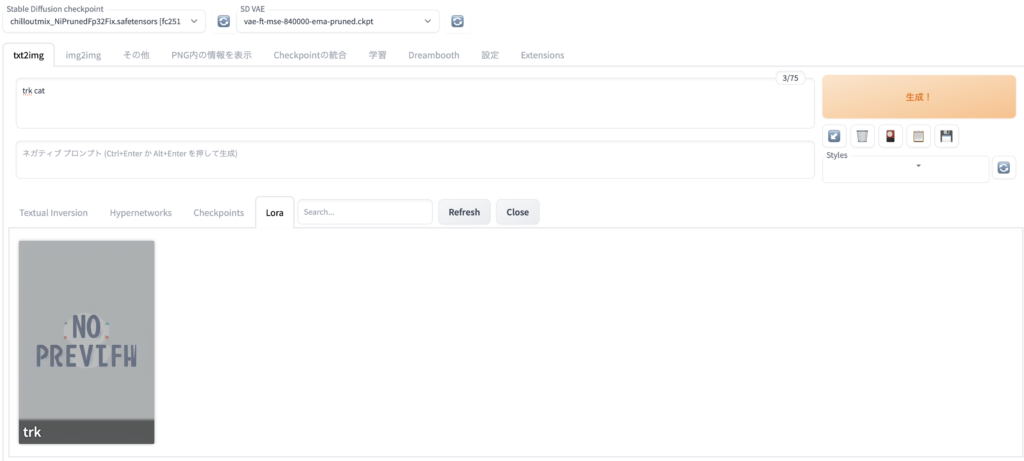
- Positive プロンプトにidentifier classを入力
- 花札マークをクリック
- Loraタブの適用したいLoRAをクリック
上記の例ですと、プロンプトには「trk cat」を入力します。
あとは「生成!」をクリックすると夢の画像が生成されるはずです!
ただ、LoRAを作成しても思い通りの画像を生成できないことがあります。
すぐに諦めて再学習する前にいろいろ試してみましょう。
LoRA作成のコツ、画像生成のコツをまとめましたので、参考にしてみてください。



コメント