
Stable Diffusion のファインチューニングといえばLoRAです。
手軽に作れて強力であることから多く採用され、LoRAの派生系も多く誕生しています。
この記事では、LoRAとLoRA派生系について少し技術や理論を交えて解説します。
この記事を読めば、現在のLoRAの発展状況を知ることができます。
なるべく難しくならないよう、なんとなくわかった気になれるよう解説します。
LoRAの派生系
LoRAには多くの派生系があり別名もあるため、整理します。
- LoRA(LoRA-LierLa)
- LyCORIS
- ┣ LoCon(LoRA-C3Lier)
- ┣ LoHa
- ┣ (IA)^3
- ┣ LoKR
- ┗ DyLoRA
大きく分けるとLoRAとLyCORISになります。
LoRAとそのLoRAを発展させたLyCORISです。
LyCORISはKohakuBlueleaf氏により命名されました。
カッコ内の名称は別名で、kohya氏により命令されました。
kohya氏のスクリプトで作成できるのは、LoRA、LoCon、DyLoRAです。
- LyCORIS・・・LoRAの発展系をまとめたプロジェクト
- DyLoRA・・・効率的なLoRAの学習手法
- それ以外・・・ファインチューニング手法
このように分類することができます。
それでは1つずつ理論を見ていきます。
LoRA
Low-Rank Adaptation
中間層(Adapter)のことで、これをニューラルネットワークに差し込むことで省メモリ化を実現します。
Stable Diffusionにおいては、Transformerのself-attention層の間に差し込み、ファインチューニングします。もう少し言うと、線形層(全結合層)の間に差し込みます。
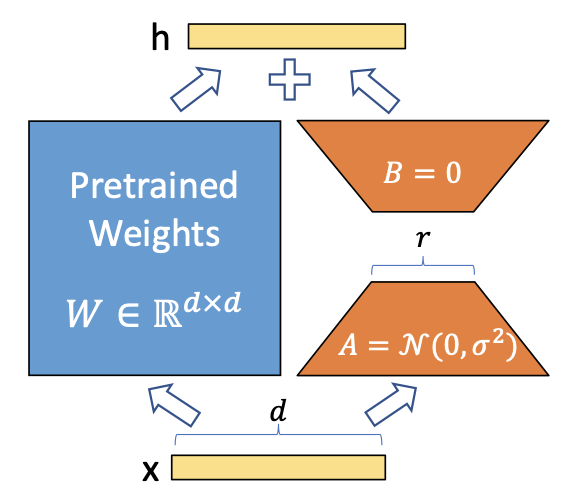
- X:ある層
- h:次の層
- d:ノード数
- r:ランク数
- W:重み
- A,B:低ランク行列
上図はNNにおけるある層から次の層への順伝播を表しています。
- 通常:h = W・X
- LoRA:h = W・X + A・B・X
通常の順伝播だとただの線型結合ですが、LoRAはある層をある層+低ランク行列に分解します。
そして低ランク行列のみを学習することによって、省メモリで済むというわけです。
このランクというのは行列の階数のことです。
特異値分解における低次元近似と同じ意味合いのことをしています。(たぶん)
全情報を使うのではなく、1〜k次元までで全体の情報を表現しようというモチベーションの次元圧縮です。
Stable DiffusionでLoRAを作る方法は以下で紹介しています。

ファインチューニングのしかた
ここで少し話題がそれますが、非技術者の間でも話題になっているchatGPT。
chatGPTは、大量データで事前学習したモデルを元に作られています。
この大量データで事前学習し幅広いタスクに対して汎用性が高いモデルのことを基盤モデル(Foundation Model)と呼びます。
基盤モデルはBERT、GPT、CLIPとかのことです。
CLIPはStable Diffusionにも使われており汎用性が高いです。
大量データを使うということはそれだけネットワークも大規模になります。
そんなモデルをファインチューニングするとき、ネットワークを丸々学習させるのではなく、ネットワークの一部のみを学習させるというのが現在の主流です。
学習時間、GPUメモリ、電気代など減らせる分は減らしながら、ちゃんと表現力を持たせるというわけです。
LoRAはまさにこの省メモリを実現しています。
ネットワーク全体を学習:DreamBooth
ネットワーク一部を学習:LoRA
というわけね。
LyCORIS
LoRA beYond Conventional methods, Other Rank adaptation Implementations for Stable Diffusion
LoRAを発展させた手法(LoCon、LoHa、(IA)^3、LoKR)と最適なランクのモデルを選択するための効率的な学習手法(DyLoRA)の総称のことです。
LoCon
LoRA for Convolusion Network
(LoRA-C3Lier)
LoRAでは線形層(全結合層)に対して中間層を差し込みましたが、
LoConでは非線形層(畳み込み層)にも中間層を差し込んでファインチューニングします。
- LoRA:Tranformerブロック(緑色)のみ学習
- LoCon:Resブロック(黄色)も学習
Stable Diffusionにおいては、非線形層(畳み込み層)の3×3カーネル(フィルタ)に対して適用します。
LoRAより多くの層を学習させますので、表現力は向上します。(その分ネットワーク容量は大きくなります)
ですのでLoRAより低いランクでも充分学習できることになります。
LoConをローカル環境で作成する方法は以下で紹介しています。

非線形層を線形層のように扱う
ネットワークには非線形層がたくさんあるし、
ここにも学習を効かせたいよな〜
LoRAは線形層を分解して元に戻していたけど、
非線形層も分解して正しく元に戻せるのだろうか?
ということで
下図のように式変形させることで、非線形層も線形層のように計算できる!
となったのでLoRA→LoConと発展しました。

LoHa
LoRA with Hadamerd Product Representation
LoRAでは低ランク行列A, Bをただの行列積で計算していましたが、
行列A, Bをアダマール積で計算するのがLoHaです。
アダマール積については以下のサイトがわかりやすいです。
行列計算を知らない人からすると、行列の積といえばアダマール積だと思うような計算です。
(かけ算といえばこうするんでしょ、という第一印象の話です。)
https://mathlandscape.com/hadamard-prod/

上図のように同じ形ですと、LoRAよりLoHaの方がランクの制約が緩いです。
- LoRA:2r
- LoHa:r2
ということは、LoRAより全体を表現可能である。
さらに言い換えると、LoRAより低ランクで充分全体を表現できる。
と言えます。
LoKR
LoRA with KRonecker Product Representation
LoHaはアダマール積でしたが、LoKRはクロネッカー積で計算します。
DyLoRA
Dynamic search-free LoRA
LoRAで最適なランクを見つけるための学習手法です。
言い換えると、1回の学習で複数ランクのモデルを得ることができるものです。
kohya氏のスクリプトでのDyLoRAの使い方は以下で解説しています。
参考サイト
やはり本家の情報を読むと正しく理解することができます。
この記事を書くために読ませていただいたサイトを紹介します。
Git
- LoRA:https://github.com/microsoft/LoRA
- LoCon:https://github.com/KohakuBlueleaf/LyCORIS/tree/locon-archive
- LoHa、LyCORIS:https://github.com/KohakuBlueleaf/LyCORIS
- DyLoRA:https://github.com/huawei-noah/KD-NLP
論文
- LoRA:https://arxiv.org/abs/2106.09685
- LoHa:https://arxiv.org/abs/2108.06098
- (IA)^3:https://arxiv.org/abs/2205.05638
- DyLoRA:https://arxiv.org/abs/2210.07558
有用サイト
- LoRAについて:https://speakerdeck.com/hpprc/lun-jiang-zi-liao-lora-low-rank-adaptation-of-large-language-models
- 畳み込み層への拡張:https://note.com/gcem156/n/nc1555befb09f
まとめ
LoRAは日々発展しており、これからも進化し続ける気がします。
Civitaiに登録されているモデルもLyCORISが増えてきました。
この記事でLoRA界隈の現状を知ることができていれば幸いです。
間違った情報がありましたら教えていただければ幸いです。


コメント