
ネット上にある素晴らしい画像について、自分もそんな画像を生成したいと思ったことはありませんか。
ただ、プロンプトを想像して入力しても思い通りの画像が生成されないことは多いことでしょう。
それだったら、AIはその画像をどう捉えているのか、どういうプロンプトで構成されているのか見てみましょう。
AIの気持ちを理解したら画像生成の幅が広がるかもしれません。
ネットにあるあの画像、私も作りたいな〜
この記事ではCLIPと呼ばれる手法で、画像からテキスト(プロンプト)を取得する方法を紹介します。
画像からテキスト、image2text、image to text、img2txt、i2tなどと呼ばれている処理です。
CLIPとは
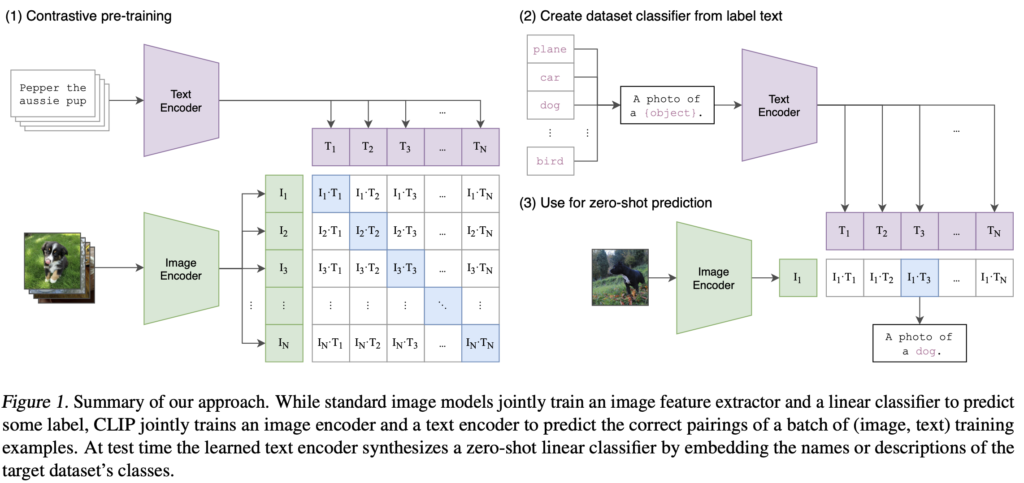
Contrasive Laungage-Image Pretrainingの略で、言語(テキスト)と画像の学習手法のことです。
CLIPで学習させることにより、文字としての単語と絵としての物体の類似度がわかります。
類似度がわかる = 近い意味のものに変換できる ことを意味しますので、
プロンプトから画像、画像からプロンプトに変換できるというわけです。
もう少し詳しく説明しますと、
テキストのエンコーダ:Transformer
画像のエンコーダ:ViT(Vision Transformer)とかResNet
で単語と物体をそれぞれembedding(ベクトル化)します。
行方向に単語、列方向に物体のベクトルを並べた行列について、self-Attentionで類似度を算出していくという流れです。
ただのTransformerだと行も列も単語でしたが、CLIPでは単語と画像を使うというわけです。
さらに詳しく知りたい方は以下を読むとよいです。
https://deepsquare.jp/2021/01/clip-openai/
論文:https://cdn.openai.com/papers/Learning_Transferable_Visual_Models_From_Natural_Language_Supervision.pdf
1. image to text @web
以下のサイトで、画像をWebブラウザにアップしてプロンプトを取得できます。
ネットに画像を上げるのに抵抗がない方にとって、最も手軽な方法です。
いくつかありますがどれもやってることは同じです。
CLIP Image2Text:https://huggingface.co/spaces/henryu/Clip-image2text
CLIP Interrogator:https://huggingface.co/spaces/pharma/CLIP-Interrogator
CLIP Interrogator2:https://huggingface.co/spaces/fffiloni/CLIP-Interrogator-2
使い方は以下のとおり。
fastを選択すると生成が速くなります。
- 画像入力
- CLIPモデル選択
- Generate Prompt / 送信
2. image to text @Stable Diffusion Web UI
Stable Diffusion Web UIを使っている方は、既にUIで実行できます。
- 画像入力
- Interrogate CLIPボタンクリック
初回実行時はCLIPモデルとか必要なものをダウンロードしますので、時間がかかります。
Stable Diffusion をローカルで構築する方法は以下を参考ください。

3. image to text @ローカル
どうしてもローカルで実施したい。
画像をネットにアップロードするのに抵抗がある。
そんな方は自分のPCに環境を構築しましょう。
画像が流出しないか心配よね。
やることは、先ほど紹介したWebで動くプログラムをローカルに持ってくるだけです。
ここではhenryu氏のプログラムを使う方法を紹介します。
準備するもの
- henryu氏のプログラム
https://huggingface.co/spaces/henryu/Clip-image2text/tree/main - CLIP interrogator
https://github.com/pharmapsychotic/clip-interrogator
プログラムはapp.pyのみです。
CLIP interrogatorはpythonパッケージ(clip_interrogator)として使用します。
その他に必要なpythonパッケージはrequirements.txtに書いてくれてますので参考にしてください。
CLIPTextModelWithProjectopnがtransformersに存在しない!となどのエラーが出る場合、transformersのバージョンが古い可能性があります。
以下のコマンドを実行し、transformersを最新化しましょう。
pip install git+https://github.com/huggingface/transformers実行方法
以下を実行すると、127.0.0.1:7860に起動します。
ブラウザで開いて後はWeb版と同じように使うことができます。
python app.py --share画像生成するためではなく単純に、この画像はAIからしたらどう見えているんだろう、とCLIPを使ってみるのも面白いです。
英語の勉強にもなります。
CLIPは、4億ペアの画像-テキストデータセットで学習したらしいです!
CLIP生成のプロンプトを見ると、どんな画像を使って学習したのかも少し垣間見えますね〜

arafed asian woman in a suit posing for a picture, cleavage, , opening, model エリサヘス s from acquamodels, japanese live-action movie, beautiful sexy woman photo画像(左)とCLIP生成プロンプト(右)


コメント