
Stable Diffusionで画像生成したいとき、Web UIを構築し自分でいろいろカスタマイズしながらというのが主流かと思います。
しかしそれだとハードルが高く、構築途中でエラーが発生し挫折してしまうこともあります。
手軽にStable Diffusionってどんな感じ?画像生成してみたいよーという方におすすめのものがあります。
それが「DiffusionBee」というアプリです!
DiffusionBeeとは
DiffusionBeeはDivam Gupta氏により開発されたデスクトップアプリです。
WindowsでもMacでも動作します。
GPUを搭載していなくても画像生成ができるため、とても敷居が低く便利です!
DiffusionBeeのダウンロード
以下のサイトからダウンロードできます。
https://diffusionbee.com
「Download」ボタンを押下すると、以下のような画面が表示されます。
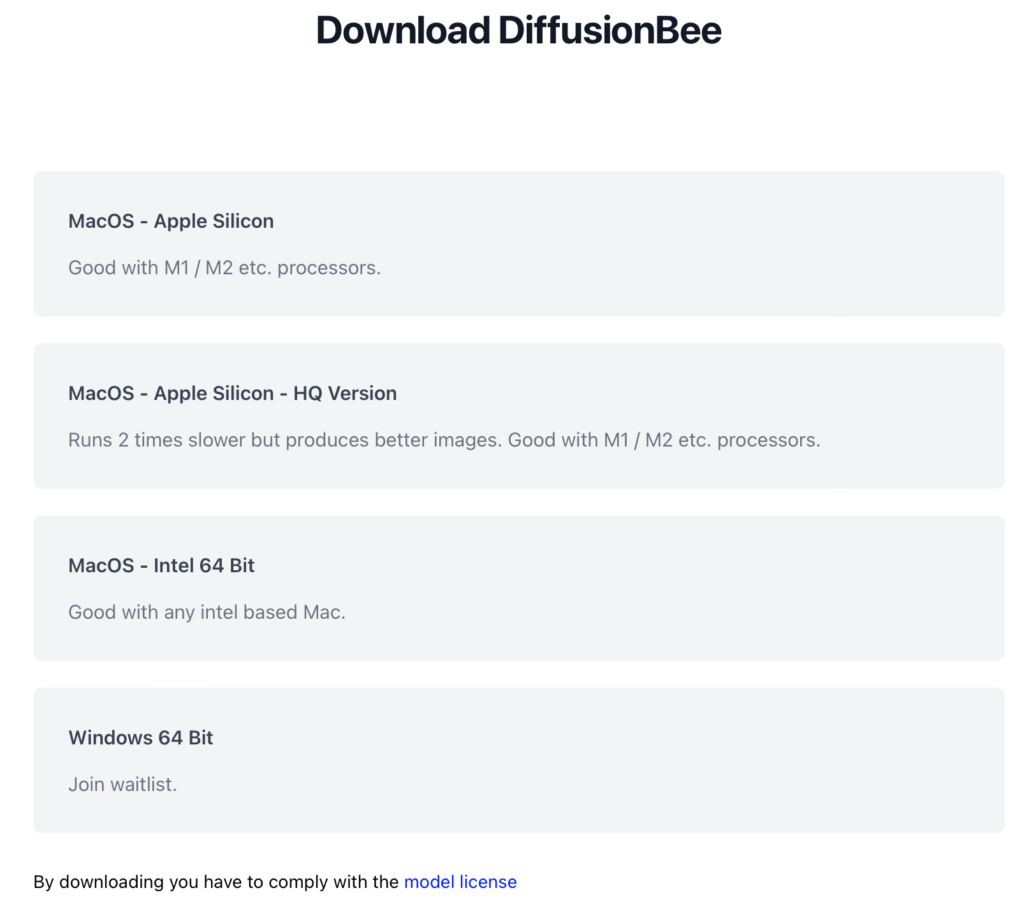
ダウンロードしたいバージョンをクリックしてください。
- MacOS – Apple Silicon・・・M1/M2チップ搭載のMacの方、これです。
- MacOS – Apple Silicon – HQ Version・・・より高性能なバージョンです。生成時間は倍かかります。
- MacOS – intel 64 Bit・・・M1/M2チップを搭載していないMacの方、これです。MacのGPU(mps)がなくても動くのは嬉しいですね。
- Windows 64 Bit・・・Windowsの方、これです。
DiffusionBeeの起動
ダウンロードしたアプリアイコンをクリックするだけです!
初回起動時はモデルのダウンロードが走りますので、少し時間がかかります。
デフォルトのモデルはStable Diffusion v1.5のfp16版のようです。

DiffusionBeeの使い方
Text To Image
単語から画像を生成します。
最初はPositiveプロンプトしか入力できないようになっていますので、「Options」からNegative PromptをEnableにしましょう。
その他のオプションについても色々試しながら画像生成してみてください。
| オプション | 意味 | 備考 |
| Number of images | 一度に生成する画像数 | |
| Batch size | 一度に処理するプロセス数 | メモリに余裕があれば1より大きく |
| Resolution | 生成する画像サイズ | |
| Steps | 画像生成の繰り返し回数 | 多いほど良い画像になりがち |
| Guidance scale | プロンプトの反映度合い | |
| Seed | ノイズ | 気に入った画像を生成できたらメモっておく |
| Custom model | 自前モデルの指定 | 自前モデルはSettingsのAdd New Modelから追加 ckpt形式しか追加できない |
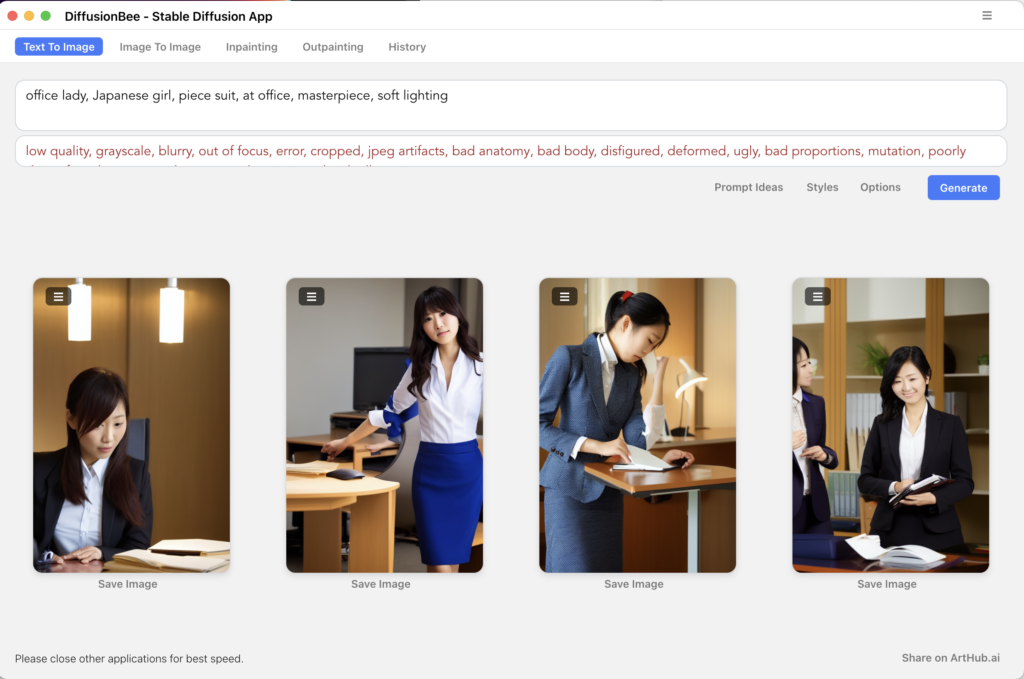
OLさんを生成してみました。
改善の余地はありますが、お手軽に画像生成できました。
Image To Image
画像から画像を生成します。
ここからでもInpaintingができます。
画像を入力し「Remove Mask」を選択し、消したい/変更したい箇所を塗りつぶします。
Optionsにある「Input Strength」はマスクした箇所をどれくらい保持するかの度合いです。
値が小さいほどマスク部分を大きく描き直します。


先ほど生成した画像を使ってImage To Imageをしてみました。
日本人っぽかったのが外国人っぽくなりましたね。
Image To Imageは画風変換をするときによく使います。
Inpainting
画像の一部を生成し直します。
Googleの消しゴムマジックもInpaintingです。
画像を入力し消したい/変更したい箇所を塗りつぶします。
以下のように赤紫に塗りつぶした部分がマスクとなります。
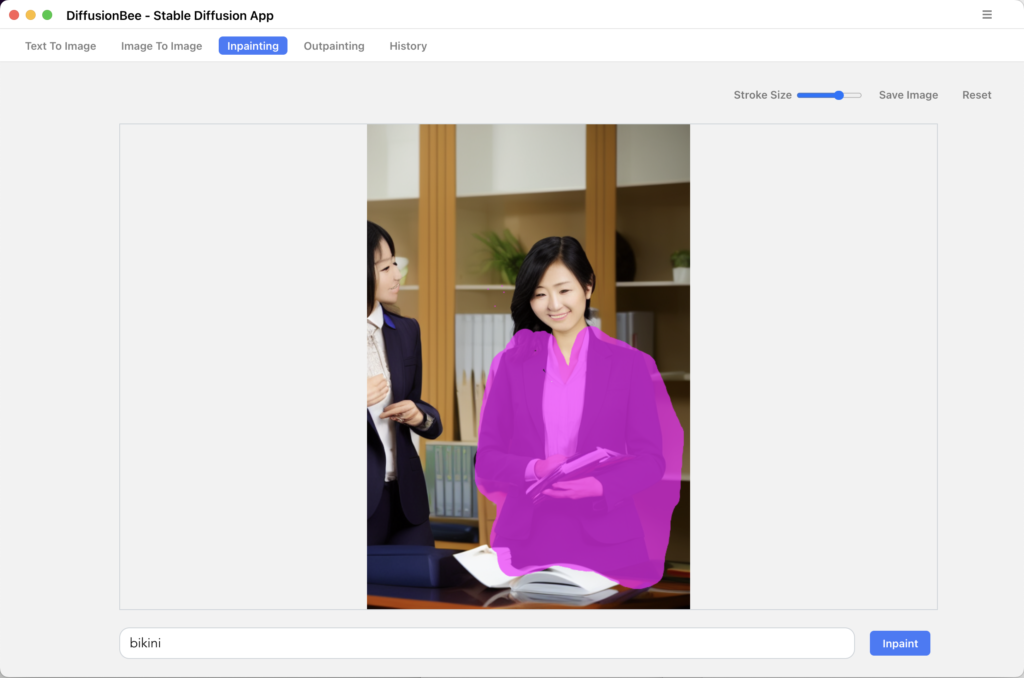

スーツをビキニにしてみました。
Outpainting
画像外を生成します。
元画像の絵柄を保持したまま、続きをAIが描くイメージです。
画像を入力し、続きを描いてほしい箇所に青い枠を持っていきます。
512×512の青い枠部分を描いてくれます。
入力画像のサイズを変えることができるため、好きな部分を拡張できます。(青い枠の大きさは固定です)


左の女性の左側を書き足してもらいました。
プロンプトに「1girl」と指定したためか、文字がたくさんついてきました。


画像全体を書き足してもらいました。
いい感じに拡張されてますね。
その他
生成した画像の情報を見たい場合、「History」タブをクリックします。
シードを含め使用したパラメータを確認することができ、再度生成する際に便利です。
まとめ
DiffusionBeeは手軽にStable Diffusionを体験できる優れものです。
ただ画像生成してくると欲が出てくるものです。もっとこういう画像を作りたい、他のモデルやパラメータだとどうなるか試したいなど。
そうなってきましたら、Stable Diffusion Web UIに手を出し、自由な画像生成ライフをお楽しみください。


コメント